I didn’t really catch this at first, but I’m not sure I understand what you are asking.
Are you asking if my scene turns off every switch and bulb at once? Or are you asking if I have my scene set up like:
“Movie” Scene:
-Family room bulb 1
-Family room bulb 2
-Family room lamp switch 1
-Family room lamp switch 2
-Family room ceiling switch
-etc
vs
Family Room Lamp Group:
-Family room bulb 1
-Family room bulb 2
-Family room lamp switch 1
-Family room lamp switch 2
“Movie” Scene:
-Family Room Lamp Group
-Family room ceiling switch
-etc
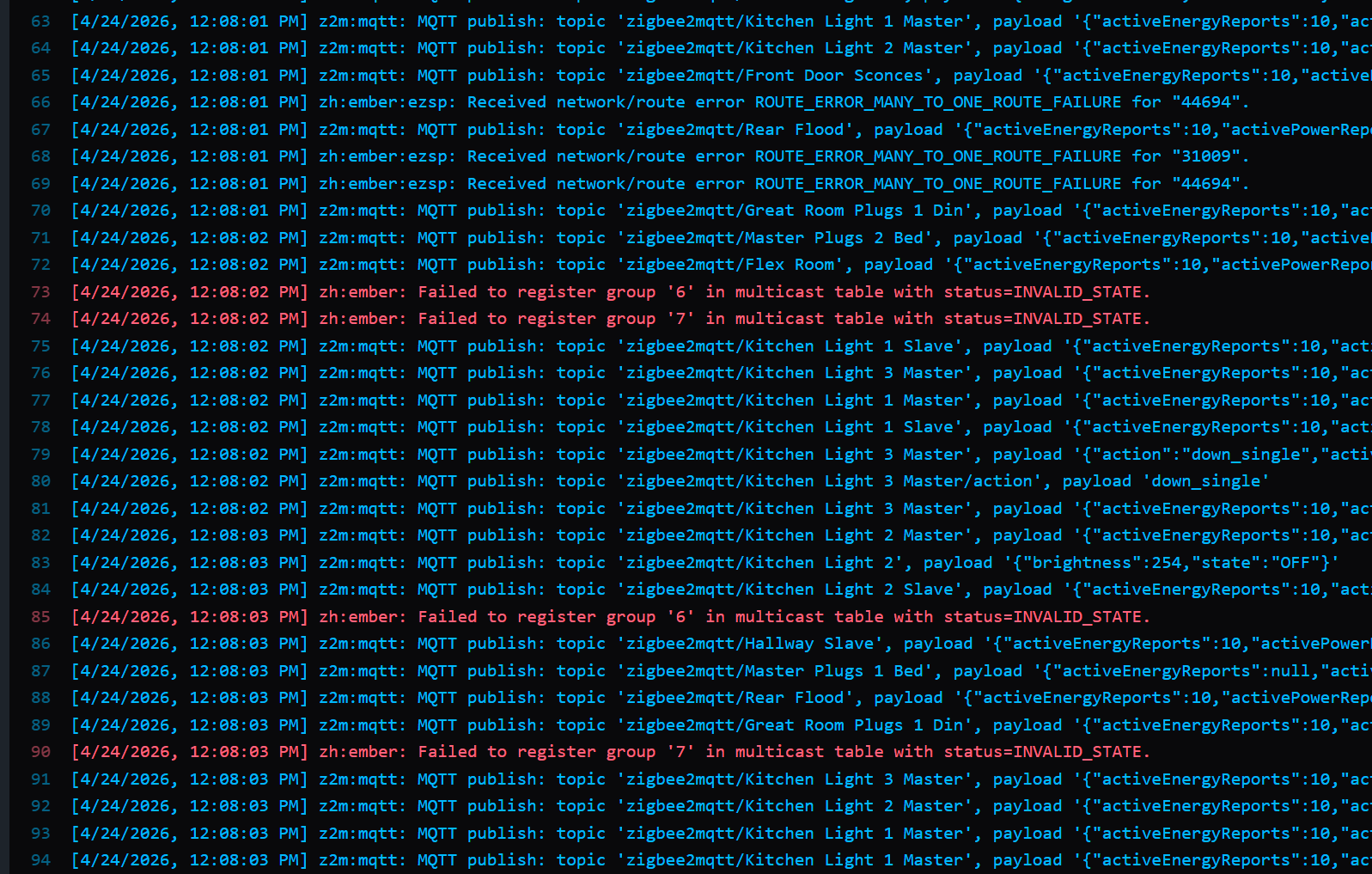
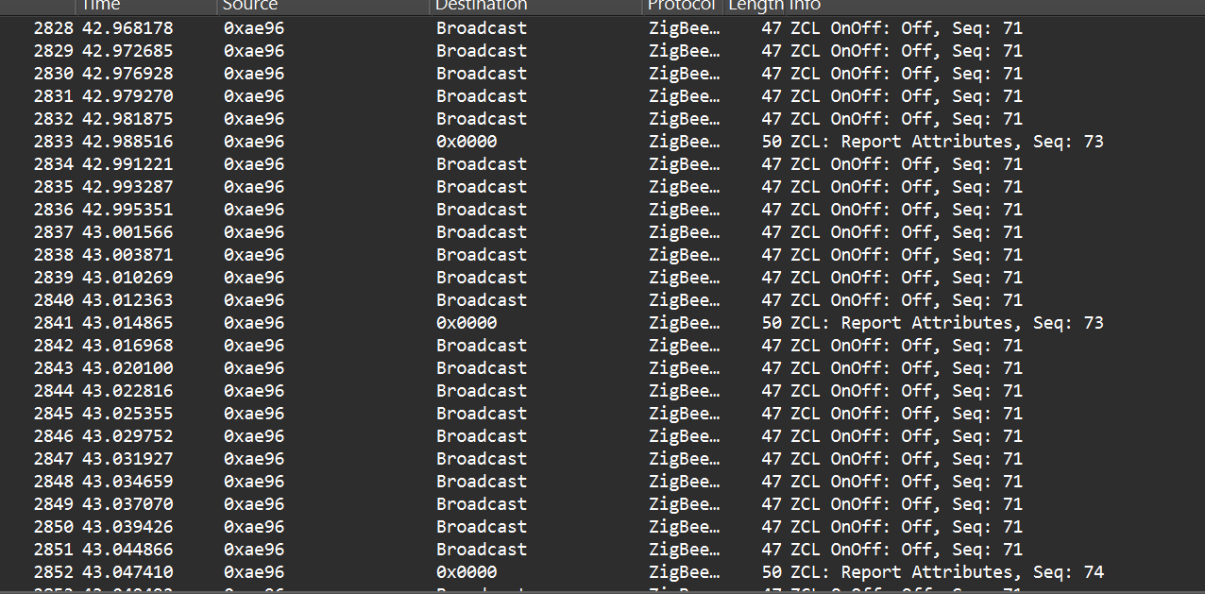
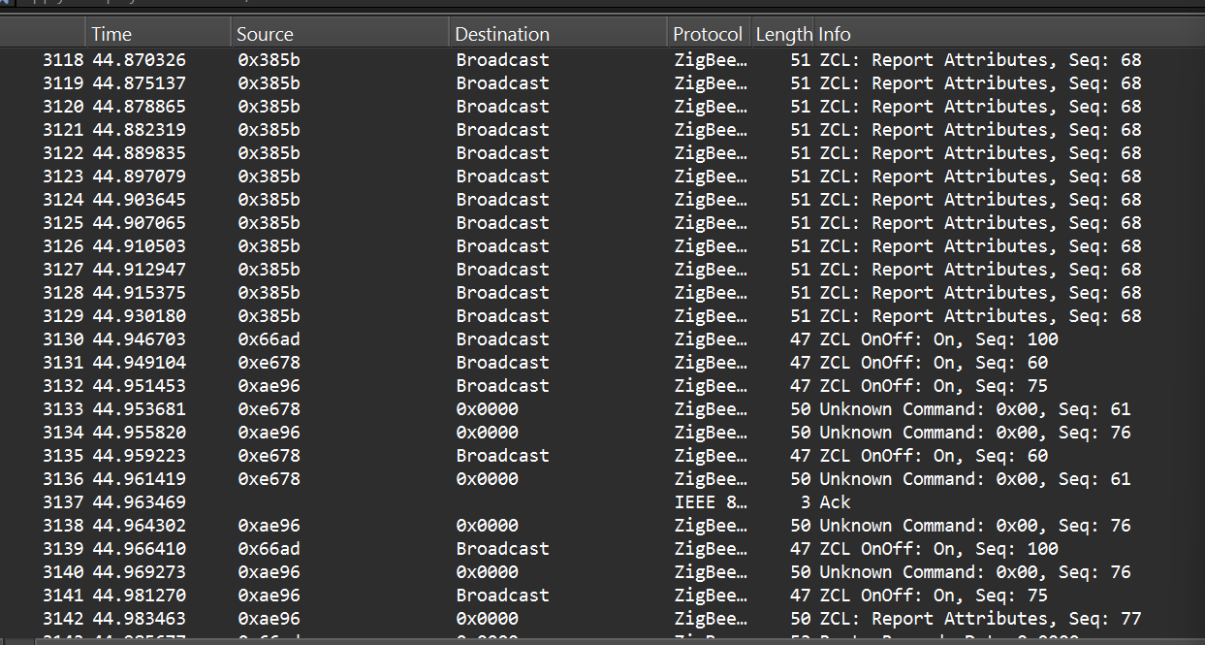
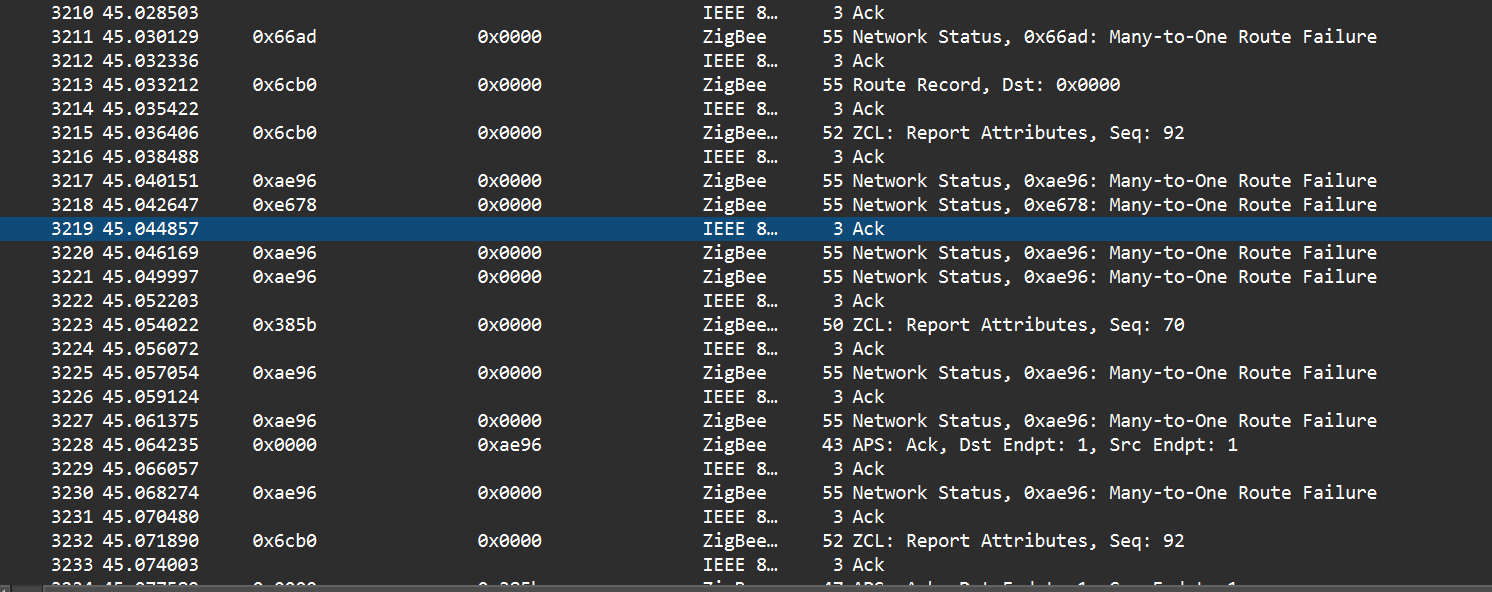
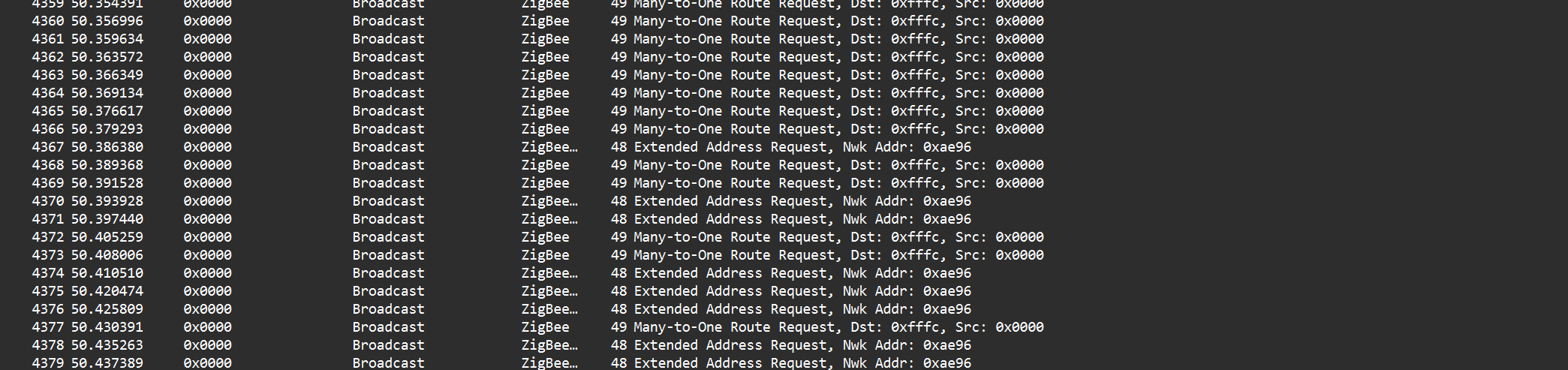
I have it set up the second way. I guess I never checked specifically if the lamps and switches turned off separately, but I don’t think they do. I just think I have 20 different lights that all need to turn off at once, and in the time that a scene is allowed to try to activate, they do not all succeed at turning off. In fact, I just realized I have a screen recording of this from the home assistant app.

You can see how it turns off the lights 6 or so at a time. And then by the time it gets to the end, it stopped trying to turn them off.
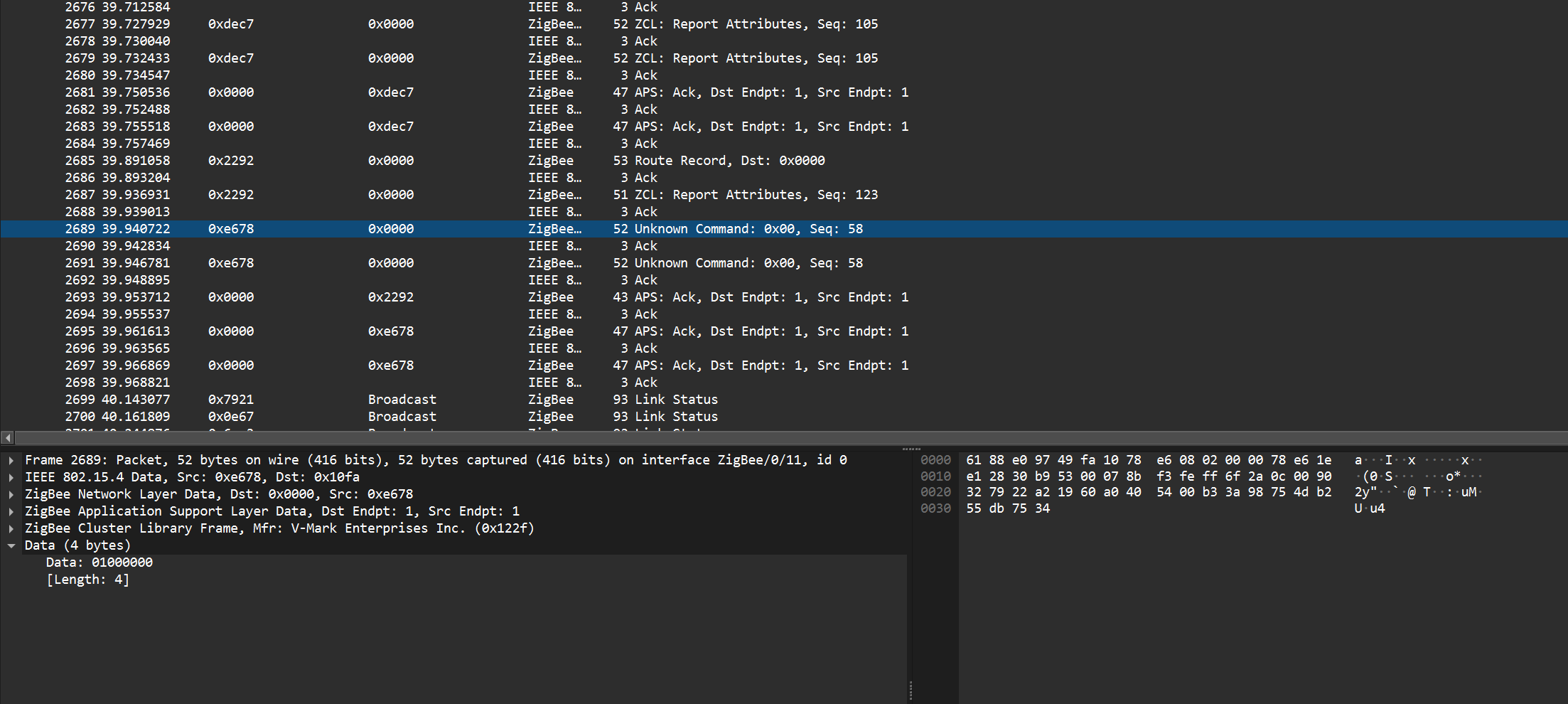
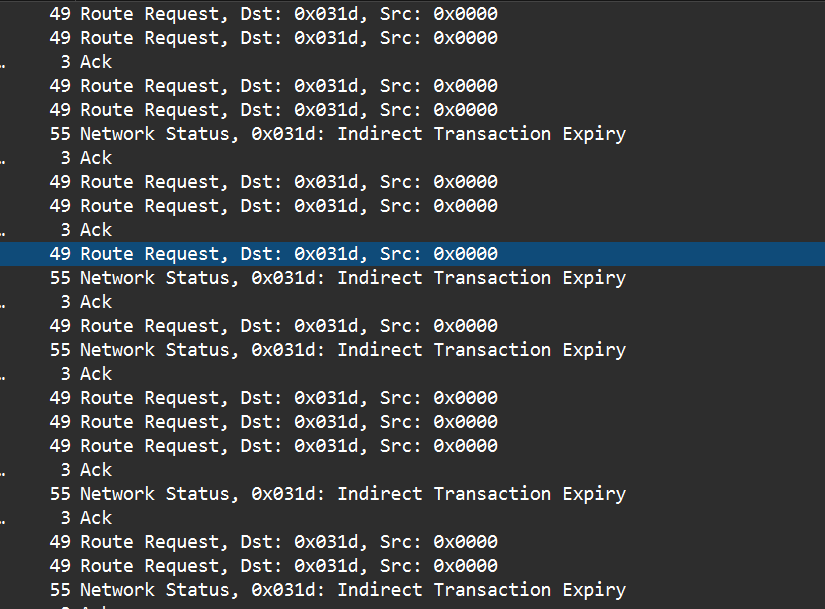
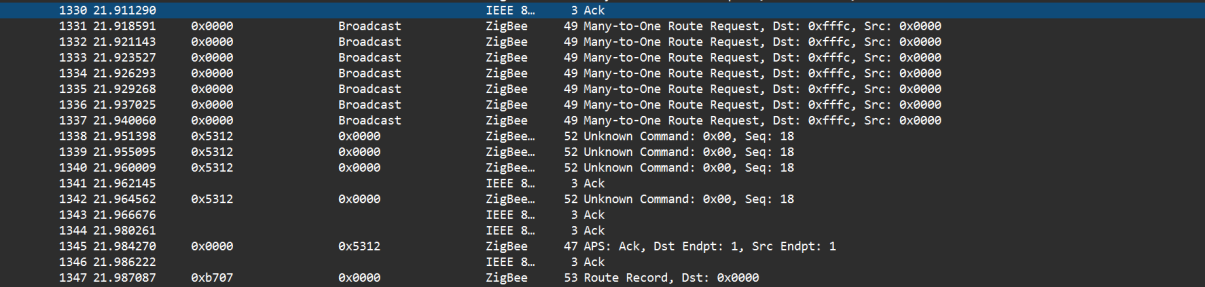
Is there something specific you would like for me to test? I got some preflashed sniffers for a good price on amazon and I’m going to try to sit down tonight and do some testing. But it occurred to me that I don’t exactly know what tests to run or how exactly to sniff the traffic.
I think I’m going to start by turning off all of the other switches to cut down the traffic, but if you would rather I not do that because that isn’t a normal test scenario I don’t have to.
I also need to try to figure out why one of the switches I have doesn’t have a functioning air gap. pulling the air gap only disconnects the ceiling light from the switch, it doesn’t power off the switch. I found one thread somewhere that suggested incorrect wiring could cause this, but also that sometimes there are bad air gaps. In the event where I would turn off every switch not in this one group, that switch presently won’t turn off. It’s on the same circuit as the group, so I can’t independently kill it from the breaker panel.