Can you share a screenshot of your reporting tab? Like this one?

Definitely- here it is for the switch I have bound to that single Hue bulb:
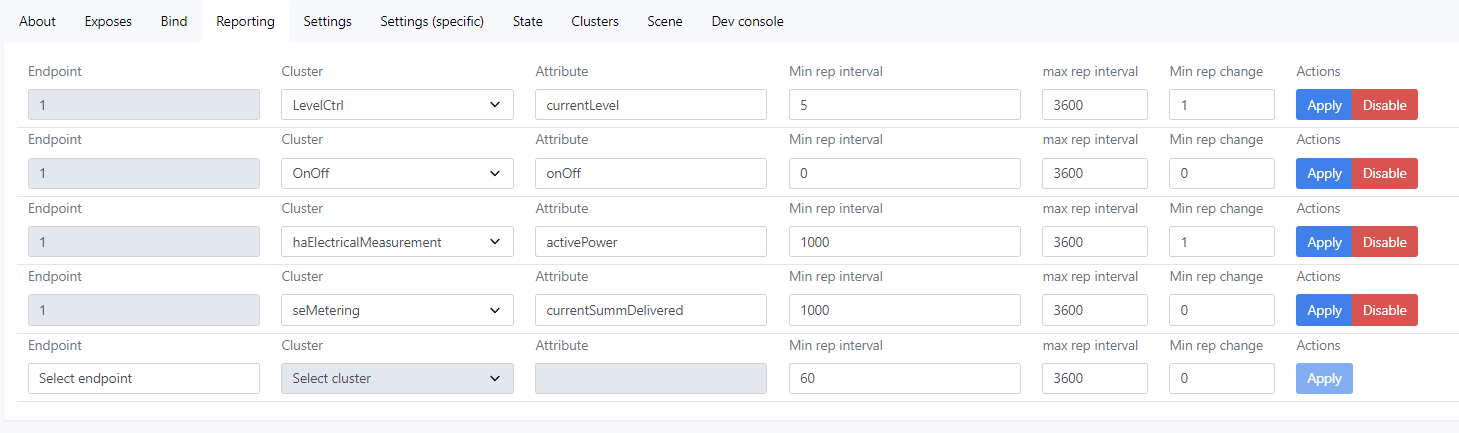
Edit: and not sure worth noting, but the hue bulb that I did the direct binding to is not on this switch’s circuit so is not impacting power reporting. All of the hue lights on this switch’s actual circuit remained off during my testing.
1 Like
Can you change the onoff reporting min rep interval to 15?
1 Like
Good thought there- I hadn’t tried that yet. I just tested and I’m still seeing the same pattern with that rep interval on onOff set to 15:
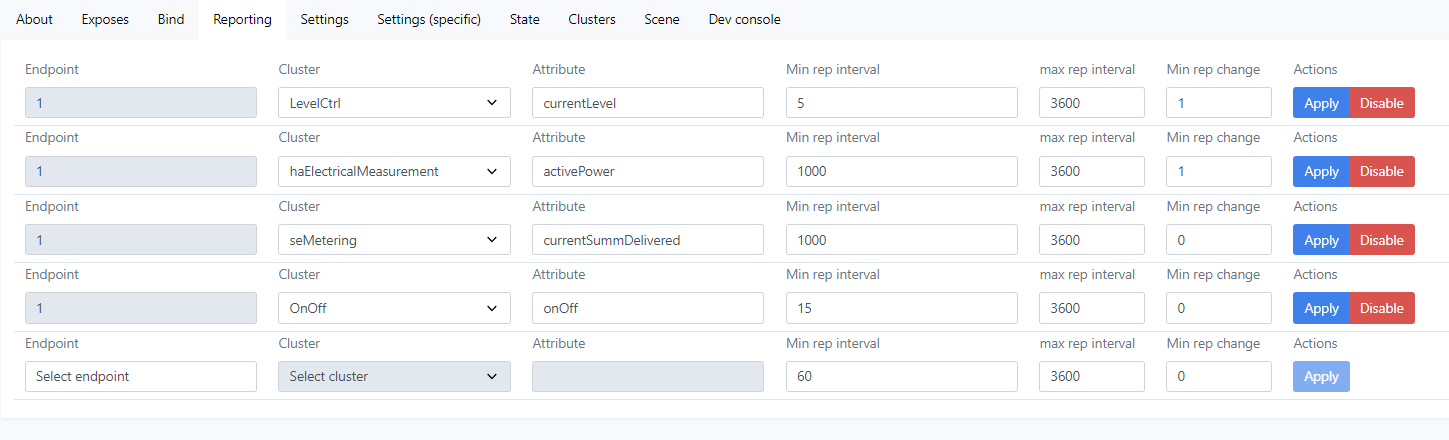
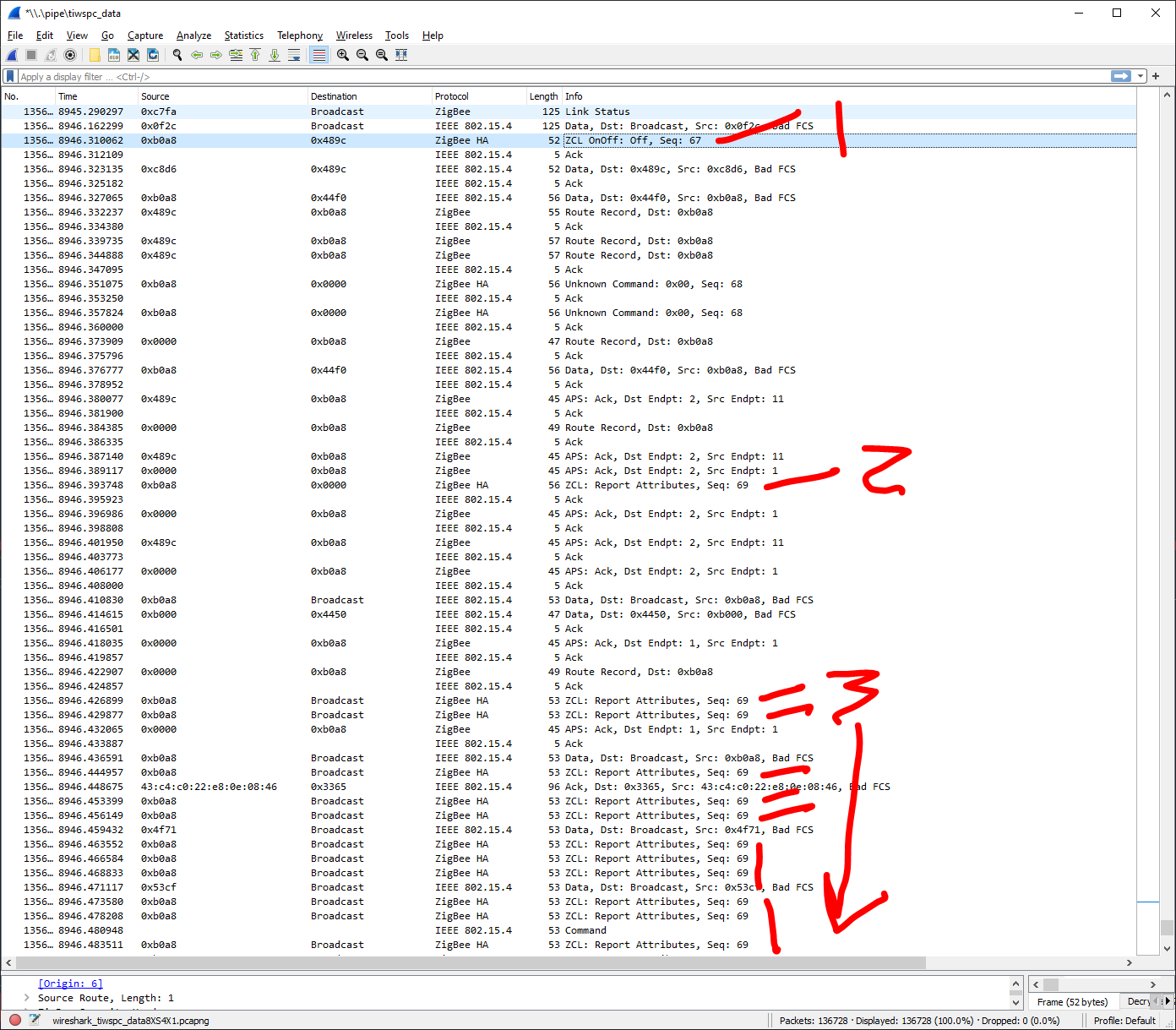
I won’t upload the full trace unless it would be useful, but you can see my highlight on the initial bind “Off” command (1), then the OnOff attribute being sent to the coordinator as seq: 69 (2), then the flood of broadcast messages start for that same seq: 69 (3) that go off the bottom of the window: appears to be one message per node in my network, which I guess makes sense for a broadcast message.
(and thank you, of course, for all the help on this, @EricM_Inovelli ! I realized I’ve just been shooting out messages without saying that)
1 Like
I posed this unack’ed broadcast flood situation as a puzzle to one of the community zigbee enthusiasts (Tony on the Hubitat forum). He says he’s just a user trying to make sense of the documentation the best he can, but perhaps this can help figure out the pattern. His response:
Hi… if the question is regarding why the Inovelli apparently broadcasts at roughly 2ms intervals (possibly in response to a missing acknowledgement), that’s a head scratcher. I’m in no position to say for sure, but I’d expect the timeout for a message (at the application level) would be multiples of 50ms, since the EMBER_APSC_MAX_ACK_WAIT_HOPS_MULTIPLIER_MS is 50ms (SiLabs defines this as the ‘per hop delay’ used to determine the APS ACK timeout value). That’s also consistent with the observed GE traces showing no issues with a response arriving within 60ms.
But that’s for an APS ACK. There are of course retries happening at lower protocol levels and those timeouts would be different…
A while back (in response to a forum post where a figure of 30 seconds was posited as a retry timeout-- that seemed kind of long) I did some digging since to see how Zigbee timeouts and retries were handled (it’s complicated!) and my takeaway was:
Accounting for retries at application, network, and media access layers, the scenario would play out like this:
a: APS > NWK (application sends message expecting APS ack)
b: NWK > MAC (check for channel clear to transmit-- nothing else transmitting, do it… if channel busy, repeat up to 5X wait period up to 7 backoff periods of 320uS each)
c: MAC transmits packet, waits for ACK, if received within 864uS, DONE (no wait if broadcast)
If NO ACK–> repeat (c:) up to 3 times, if still NO ACK, MAC reports failure to NWK layer (so 4 transmits so far)NWK layer waits up to 48ms, then retries (b:); still no ACK, repeat (b:) until 250mS elapsed, then report failure to APS layer. (at this point, have done at least 8 retries)
APS layer waits specified interval (multiple of EMBER_APSC_MAX_ACK_WAIT_HOPS_MULTIPLIER_MS) , then tells NWK layer to retry at (a:)
If still no ACK (after at least 16 retries, so far) APS layer retries all of the above starting at (a:) TWO MORE TIMES. Resulting in up to 48 transmission retries for a single unacknowledged packet…
In any event (at least in the Ember stack) the minimum application layer timeout–allowing for only a single hop-- would be 50ms. Retries more frequently than that would seem to be originating at the network or MAC layer.
From reading the thread you linked, it does seem like the observation about differences between GE and Innovelli re: default response enablement is significant. But that’s an application layer difference… and the repetetive sequence 29 broadcasts don’t seem to be waiting for APS ACK timeout intervals.
3 Likes
Wow, very interesting read- big thanks to yourself and Tony! It certainly makes me understand how in over my head I am trying to interpret any of this myself ![]() Still having fun investigating, anyhow
Still having fun investigating, anyhow
3 Likes
@mbbush wondering if we could get your thoughts?
@bgreet I’m flattered you mentioned me specifically. I also consider myself “just a user who reads documentation in detail”. I’ll try and find some time to read through this thread in the next few days and give an opinion, but no promises.
1 Like
Our engineers have identified an issue that they believe is causing the excess communication. The next firmware release should help with this. I believe it is coming next week.
13 Likes
Great news- thanks for the follow up (esp. on the weekend), @EricM_Inovelli !
2 Likes
That’s amazing! Thanks to everybody for helping to identify the issue
Just an update. Overall network is working much better, but still having rare reset issues now that I’ve finished installing the remainder of my switches. Overall incidence of the ground plate issue is around 15% out of the entire 50.
Hoping the firmware update fixes the random restarts.
2 Likes
Random restarts are because you either have a LINE or NEUTRAL wire loose.
I had this issue when dealing with a 4-gang box. Found a few loose on different switches.
These switches are very touchy (probably because of certification), so if one has a voltage drop it may cause enough drop or spike on either the LINE or the NEUTRAL of another switch in the same box and cause them to reset too almost like pulling the air gap out and push back in.
If your switches are rebooting randomly - you have a wiring issue. This is absolutely NOT a software problem.
2 Likes
This isn’t your standard restart with a relay click (like you would have with removing the air gap). I’ve had that on one switch. This is a silent restart with going through the colors of the restart and much quicker. It was happening all the time previously and with the reduction in Z2m polling has reduced markedly so definitely suggestive of software issue. Had discussion with Eric and he thinks may be related to flooding switch memory and may be resolved with new firmware coming down the pipeline that reduces network flooding.
Interesting, I have not had such issues with any switches rebooting like that. However, I have had issues where zigbee binding from switch to switch dies randomly until the switch is rebooted using the air gap. For example, in a 4 way switch scenario 1 out of 3 of the bound switches will lose their binding and need rebooted to get it to work again. Not sure what’s causing that. Happens almost daily. Seems the zigbee network is very slow the more switches added and possibly that routing is not happening properly or a network loop is occurring. Upon some testing with some test zigbee packets, it seems some switches are 100% failing to route packets to the hub. These are all switches that are not in the bad range. If I go directly to the hub it will make it every time, but if using a switch to route, it intermittently fails to get to the hub. This is even causing issue’s for non-Inovelli stuff like my door contact sensors which are failing to send data to the hub now. The switches are failing to send the packets, it’s almost like they’re not even trying or something is preventing them from doing so. Either way - I kinda wish I could turn off the ability for them to route for now until it’s fixed. Maybe @EricM_Inovelli has an idea what is causing this?
One thing I noticed is that all the switches show up as “concentratorType:Low Ram” devices.
When speaking with Hubitat support, they have sent me the following:
"A low ram concentrator is just what it sounds like. The coordinator device does not have enough memory to fill a full routing table so it only stores a partial table. When the coordinator needs to send a message to a device but does not know the route, it first has to send out a discover frame and wait for a routing response before it can actually send the message.
A high-ram concentrator is the opposite. It maintains a full routing table to each end device. This also means that a high-ram concentrator has to frequently request route information from devices that act as routers so it keep its routing tables updated. Since the coordinator knows the routes to each device, whenever it needs to send a message it can do so without having to wait for route discovery. This method usually results in much quicker response times to devices.
Low ram concentrators have to frequently send route discovery requests prior to sending a message. That’s horrible for large networks because these are effectively broadcast messages which can start to degrade a network."
@bgreet When wiggling a neutral or line, I had the switch do a reboot without the relay click. So I’d still suggest you check those connections. If the copper isn’t long enough it may just fall out even if it was tight prior to pushing all the switches in. It happened enough to me that I highly recommend looking into that as the cause. I have 60 switches installed and not one of them has rebooted like that unless a wiring issue was the cause.
All switches on firmware: v2.08
Driver version: 2022-12-12
Platform: Hubitat
Interesting, I haven’t had the same degree of issue with binding though binding messages definitely fail on occasion. I’ll triple check my wiring again but the circumstances really lead me to believe it is software mediated. Prior to changing the polling rate, every switch was rebooting every 20 minutes or so. After changing the polling rate, I catch one doing it maybe every few days. It is such a stark change before/after changing the polling.
I have 16 installed, and one of them has displayed occasional reboot behavior. It’s happened very infrequently, and only shortly after I made big additions to the network. I’m pretty good with wiring (imho)… I strongly doubt that I bungled the connections. Hasn’t happened in over 1 week (and only 3 times total since I installed my replacements ~ 1 month ago). Coincidentally, I haven’t made any changes to the network during that time, so things have been nice and stable without a lot of discovery frames flying around. Might still have excess broadcast spam out there (on 2.08), but that doesn’t seem to be enough to cause this switch to reboot. Only changes/additions to the zigbee mesh seem to make it freak out and reboot.
1 Like
Just confirming what you saw @epow . I removed one of the switches that lately decided it was going to restart every 15-20 minutes from the zigbee network. Doing so fixed the problem and no more restarts. Hopefully the new firmware fixes this. Looking forward to its release!
This topic was automatically closed 67 days after the last reply. New replies are no longer allowed.