Just received my 50 replacements and started to install them. I wanted to share my experience to see if anyone has any suggestions or has experienced similar issues and to make them known in the event they can be fixed/improved upon. I’ve installed roughly 20 so far. I’m on docker home assistant and docker zigbee2mqtt (1.28.4), using a TubesZB CC2652P router via POE, have tried both 122022 and 021921 Z-stack firmwares. I have 150 devices on my network at this point, 137 being mains powered routers. My network just prior to installing the 20 blue 2-1’s was pretty stable and responsive. I’ve also tried to change energy reporting to 1000 (though sending any changes at this point is very difficult). All switches came with firmware 2.08. Since installing I’ve encountered the following:
-
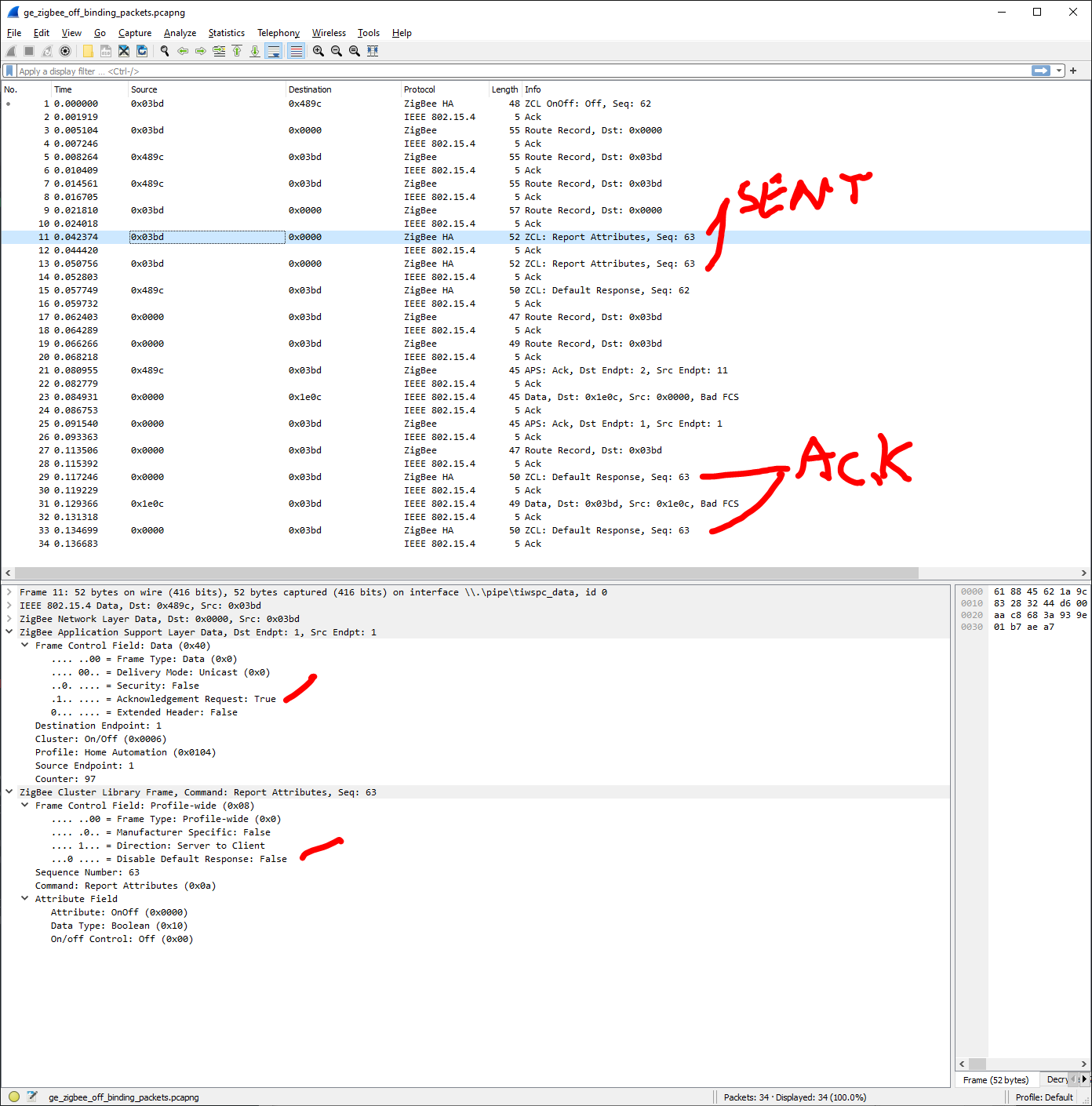
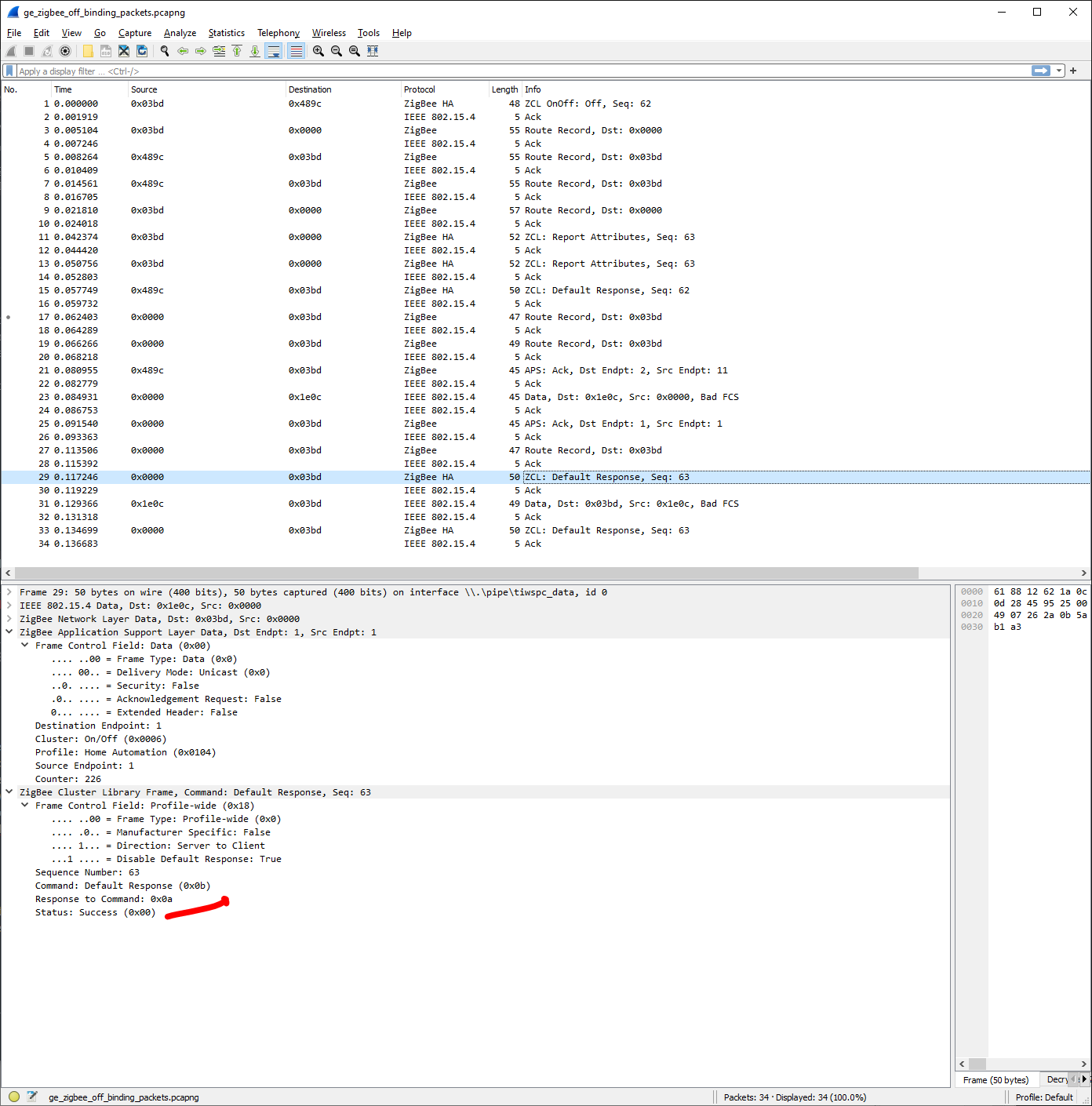
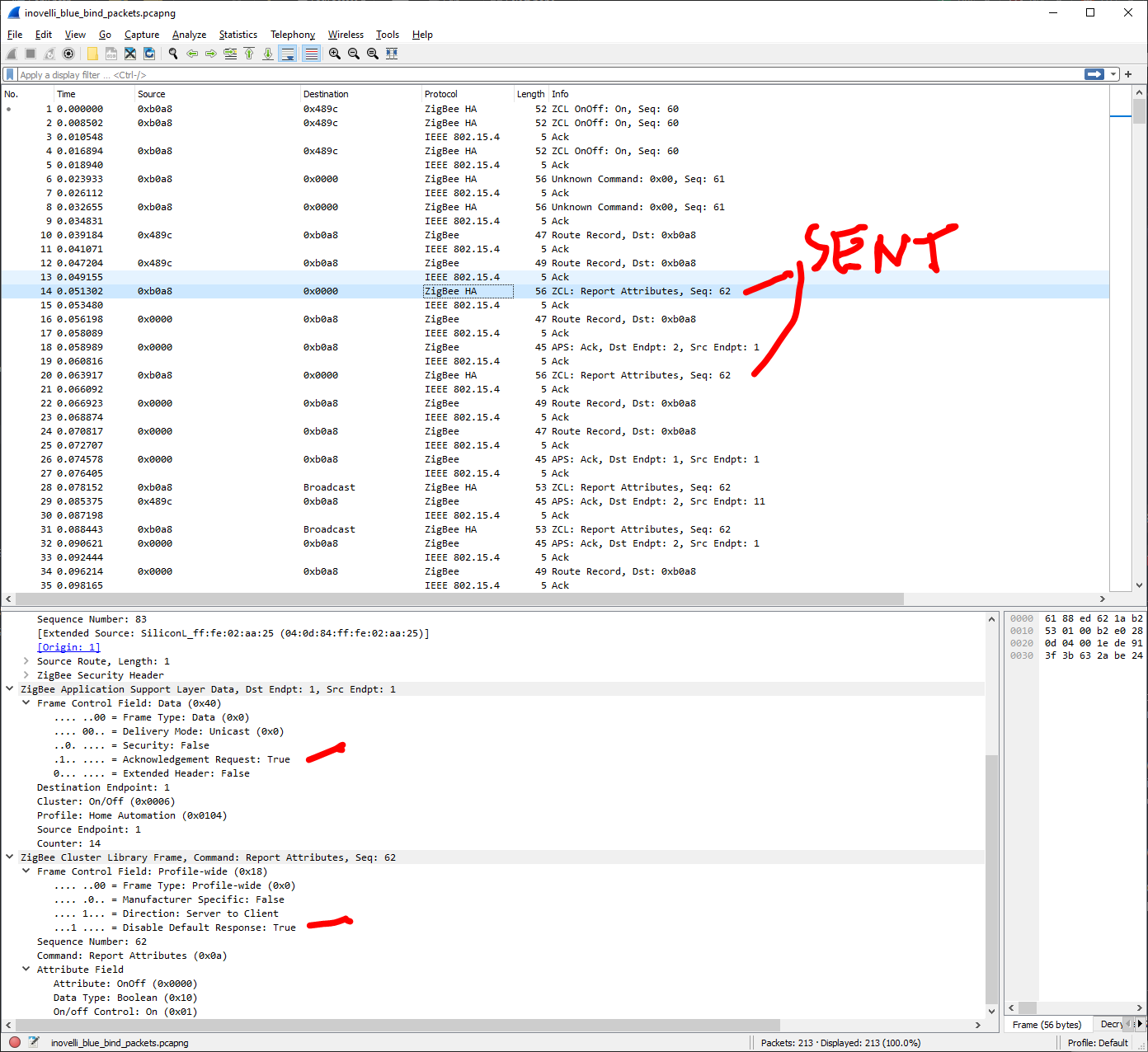
My network has become incredibly unstable and can barely interact with anything on the network. Most actions time out and are not able to be performed. Many devices are now falling off the network. Getting Data request failed with error: ‘No network route’ (205), SRSP - AF - dataRequest after 6000ms, Timeout - 57471 - 11 - 12 - 0 - 1 after 10000ms and a few other errors in my logs.
-
Bound lights (mostly Hue, though also have Eaton/Halo) work about 1/2 of the time and require multiple presses to turn lights off and on. Dimming also is not 1:1 and often it isn’t until after coming off the light switch that the dimming is reflective of the switch.
-
The Inovelli switches keep falling off the network. Sometimes pulling the air gap and resetting will fix this but not always.
-
You can not drop the plate for the ground wire in 20% of the switches to actually fit the ground wire into the plate to secure. Tried manipulating the screw and plate but its completely stuck. I ended up having to put the ground under the screw which is less than ideal/secure.
-
Random resets on some of the switches that are completely unpredictable. As if someone removed air gap and put it back in. I know neutral wiring is not an issue and it appears to occur at random.
Any feedback/thoughts would be really appreciated. Would love to make these work as I’m sure they are capable of. Thanks!
Update: Ended up removing all of them from my network and slowly reintroducing one by one and turning off energy reporting to the best of my ability. This seems to be working at the moment. If continues to be stable by tomorrow I’ll look to try to install more switches and see how it goes.